The Problem Nobody Talks About
When any agent has too many skills — and by “too many” I mean past some fuzzy threshold that depends on skill complexity and overlap — the agent will eventually go nuts.
Here’s a concrete example. I was running Hermes and had both a Gmail skill and a Google Workspace skill. They overlapped. At some point, the Gmail skill’s API went out of date. Every time the agent called it:
“Sorry, API failed. Let me directly fetch the web… oh, I don’t have access. Let me rethink… actually, wait, you have another skill that might work…”
Burning tokens. Spinning in circles. Not working.
The obvious fix — manually review and clean up the skills — doesn’t scale. Skills aren’t static. They’re more like repos: they need to be maintained. APIs change, tools break, better patterns emerge.
I needed AI to maintain the skills, not me.
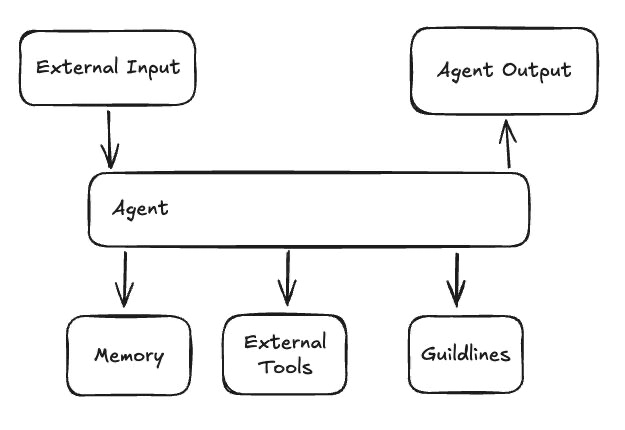
The Architecture
Here’s what I built (Codex and Claude Code wrote 100% of it, I just described the flows 😅):
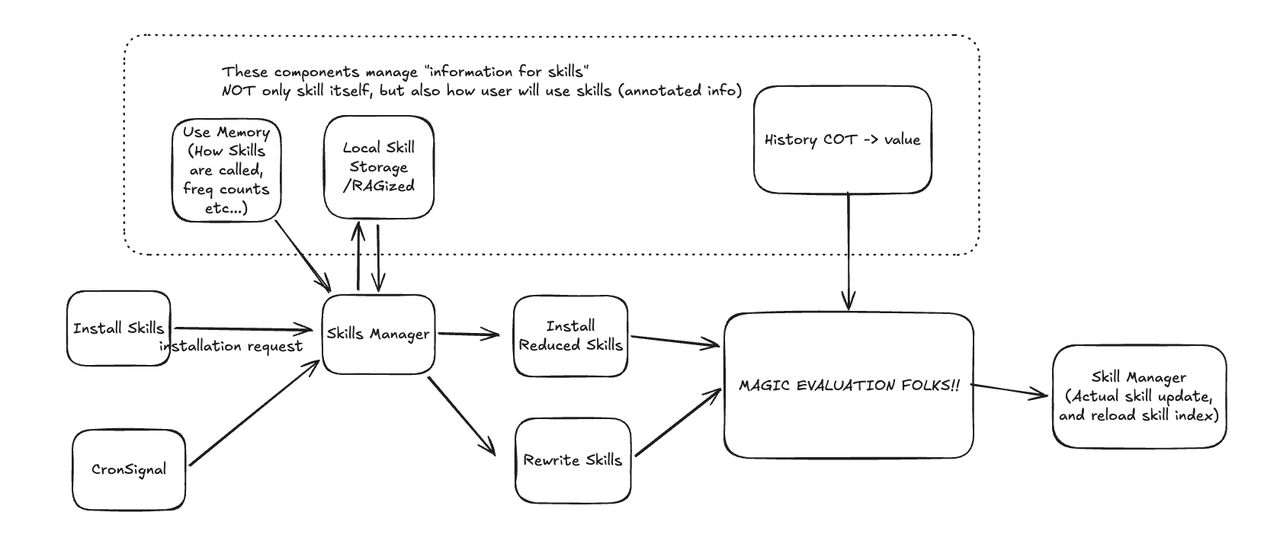
Here’s the full flow:
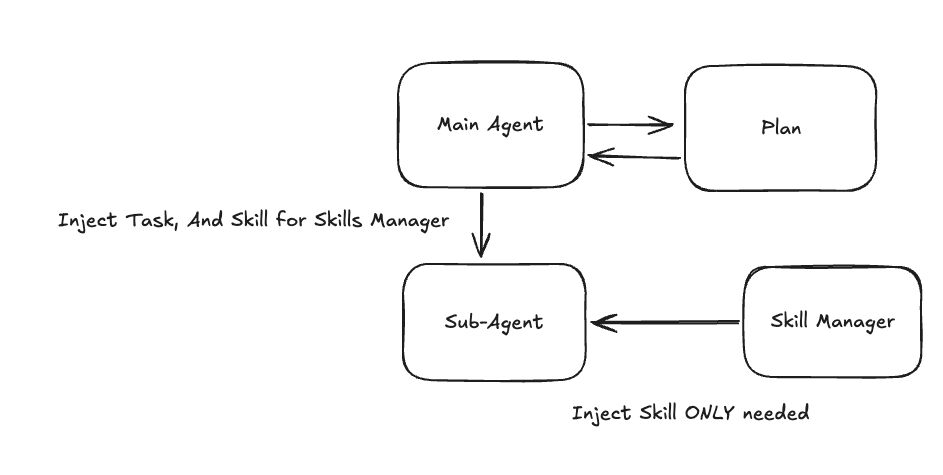
And the agent delegation model that makes it work:
1. Skill Manager with RAG-based Deduplication
Before installing any new skill, run it through a skill manager that checks for redundancy.
- Match by keyword and semantic embedding
- Also use tags: “google”, “productivity”, “stock trading” — not just embedding similarity
- At ~5k skills, this runs fast enough to be practical
If a new skill is too similar to an existing one, reject it or merge the concepts.
2. Telemetry System
Every skill call gets logged:
- Success or failure
- Chain-of-thought trace
- Token cost
Stored in local SQL + blob storage. This is the data layer that makes everything else possible.
3. Installation Filter
On every new extension/plugin/skill install, the skill manager runs first. The filter compares the new skill against existing ones and reduces overlap before it lands in the system.
4. Weekly Cron Audit
A cron job (I haven’t tuned the trigger yet — tell me a better one) does a delta review of the telemetry logs:
- Find skills with high failure rates or bloated COT
- Decide: modify the skill to be more efficient, or delete it
- If deleting, use web search to find or create a replacement
Critical: make sure your eval environment is stable before running this. You don’t want the audit job to delete a working skill because it was measured during a bad network day.
5. Main Agent Restructure
The main agent no longer holds specific skills directly. Instead:
- Main agent receives a task
- Spawns a sub-agent
- Sub-agent calls the skill manager to install what it needs
- Sub-agent executes
The main agent’s only job is managing other agents and planning. I’m still thinking about whether planning and execution should be split further — probably over-engineering at this stage.
Why This Changes the Design Fundamentally
The skill management system forces a question I hadn’t thought about clearly before: what should the main agent be good at?
My answer: not much, specifically. The main agent should be good at delegation and planning. Everything else — tool use, skill selection, domain expertise — gets handled by specialized sub-agents that spin up with exactly the skills they need.
This is closer to how real teams work. A good manager doesn’t know how to do every job on the team. They know who to call and what to ask for.
What’s Left (TODO)
- Better trigger for the audit cron (weekly is arbitrary)
- Web search integration for auto-replacing deleted skills
- Eval environment stability before running automated cleanup
- Split planning into a separate agent (maybe)
On the Birth Announcement
Yes, I buried the lede. My first baby Grace was just born. Between her and a TOP urgent work task, the Agent from Scratch series is delayed. But I’m not giving up on it. Q.Q
This is the Hermes architecture as of June 2026. The code is on GitHub — Claude Code wrote it, I just had the ideas.
]]>